
Pinterest Slashes Spark OOMs by 96% with Auto Memory Retries

Alps Wang
Apr 7, 2026 · 1 views
Taming Spark's Memory Beast
Pinterest's approach to reducing Spark OOM failures by 96% is a compelling case study in practical, large-scale data engineering. The key insight is the multi-pronged strategy: enhanced observability to pinpoint memory consumption, intelligent configuration tuning, and the game-changing Auto Memory Retries. This isn't just about throwing more memory at the problem; it's about understanding the intricacies of Spark's execution and proactively managing resources. The detailed metrics for executor memory, shuffle, and task times, coupled with adaptive query execution and data skew mitigation, demonstrate a deep understanding of the platform's behavior. This methodical approach, prioritizing visibility before intervention, is a best practice that many organizations could adopt to improve their own Spark stability.
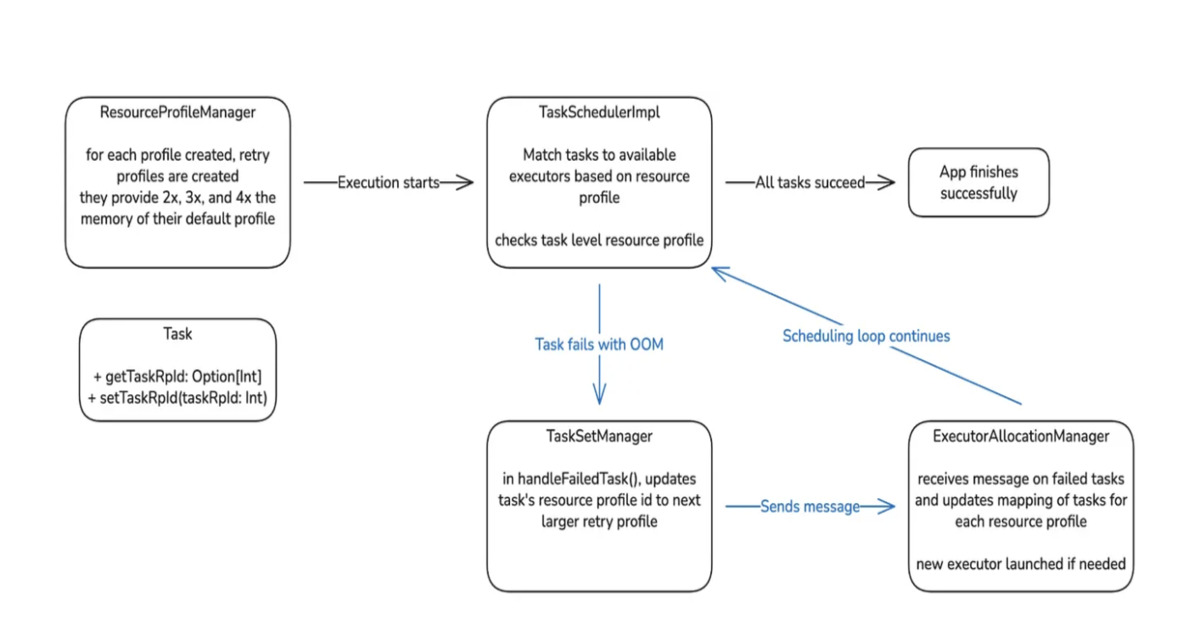
The innovation lies in the Auto Memory Retries, which automates the often tedious and error-prone process of manual memory adjustment. By allowing jobs to restart with adjusted memory configurations without altering the core logic, Pinterest has effectively reduced operational overhead and improved pipeline reliability. The staged rollout, starting with ad hoc jobs and gradually moving to critical workloads, is a testament to their disciplined engineering process, allowing for early issue detection and refinement. This strategy is highly beneficial for any organization heavily reliant on Apache Spark for memory-intensive workloads, such as recommendation systems, large-scale ETL, or machine learning pipelines. It directly addresses issues like pipeline disruption, increased on-call burden, and delayed analytics, which are common in such environments. The prospect of proactive memory allocation in future iterations further solidifies this as a leading-edge solution.
However, a potential limitation or concern might be the complexity of implementing such a comprehensive observability and retry system. While Pinterest has shared its success, the initial investment in building detailed metrics and integrating the Auto Memory Retry logic could be substantial for smaller teams or organizations with less mature DevOps practices. Furthermore, the effectiveness of Auto Memory Retries is contingent on the ability to accurately predict or infer the correct memory adjustments. If the system consistently over-allocates memory, it could lead to increased infrastructure costs, and if it under-allocates, failures might still occur. The article mentions Apache Gluten compatibility, suggesting a focus on performance, but it would be beneficial to understand the trade-offs in terms of latency or complexity introduced by these retry mechanisms. Nonetheless, the reported 96% reduction in failures is a strong indicator of success and a benchmark for others to strive for.
Key Points
- Pinterest achieved a 96% reduction in Apache Spark Out-of-Memory (OOM) failures.
- Key strategies included improved observability, configuration tuning, and Auto Memory Retries.
- Enhanced visibility involved detailed metrics for executor memory, shuffle operations, and task execution times.
- Configuration tuning optimized Spark settings like memory allocation, shuffle partitions, and broadcast joins, alongside adaptive query execution and data skew mitigation.
- Auto Memory Retries automatically restart failed jobs with adjusted memory settings, reducing manual effort.
- A staged rollout strategy was employed, starting with ad hoc jobs and progressing to critical workloads.
- Future work includes proactive memory increases for high-risk stages.
📖 Source: Pinterest Reduces Spark OOM Failures by 96% Through Auto Memory Retries
Related Articles
Comments (0)
No comments yet. Be the first to comment!