
Uber's Hive Federation: 10PB Decentralized for Zero-Downtime Analytics

Alps Wang
Apr 10, 2026 · 1 views
Decentralizing Petabytes: Uber's Hive Evolution
Uber's implementation of Hive Federation represents a sophisticated solution to the common pain points of monolithic data warehouses: scalability bottlenecks, resource contention, and governance complexities. The pointer-based migration strategy is particularly elegant, minimizing data movement and ensuring zero downtime for critical analytics and ML workloads. This approach directly tackles the 'noisy neighbor' problem and empowers domain teams with greater autonomy, which is crucial for agility in large organizations. The emphasis on automated checks, human-in-the-loop validation, and a robust recovery orchestrator highlights a mature engineering discipline focused on reliability and risk mitigation. The reclaiming of 1 PB of HDFS space is a tangible benefit, showcasing efficient resource management.
However, the article, while informative, could benefit from further detail on the operational overhead and complexity introduced by managing 16,000 decentralized datasets and their respective synchronizations. While the benefits of autonomy are clear, the increased distributed management responsibilities for individual teams might present new challenges in terms of skill sets and coordination. Furthermore, the long-term maintainability and evolution of such a federated metastore, especially as the number of datasets continues to grow, warrants deeper discussion. The article also touches upon security through least-privilege access, but a more in-depth look at how fine-grained access control is enforced across these federated datasets would be valuable for readers implementing similar solutions.
Key Points
- Uber migrated over 16,000 datasets and 10+ PB of data by federating its Hive data warehouse.
- The previous monolithic architecture suffered from scalability issues, resource contention, and governance bottlenecks.
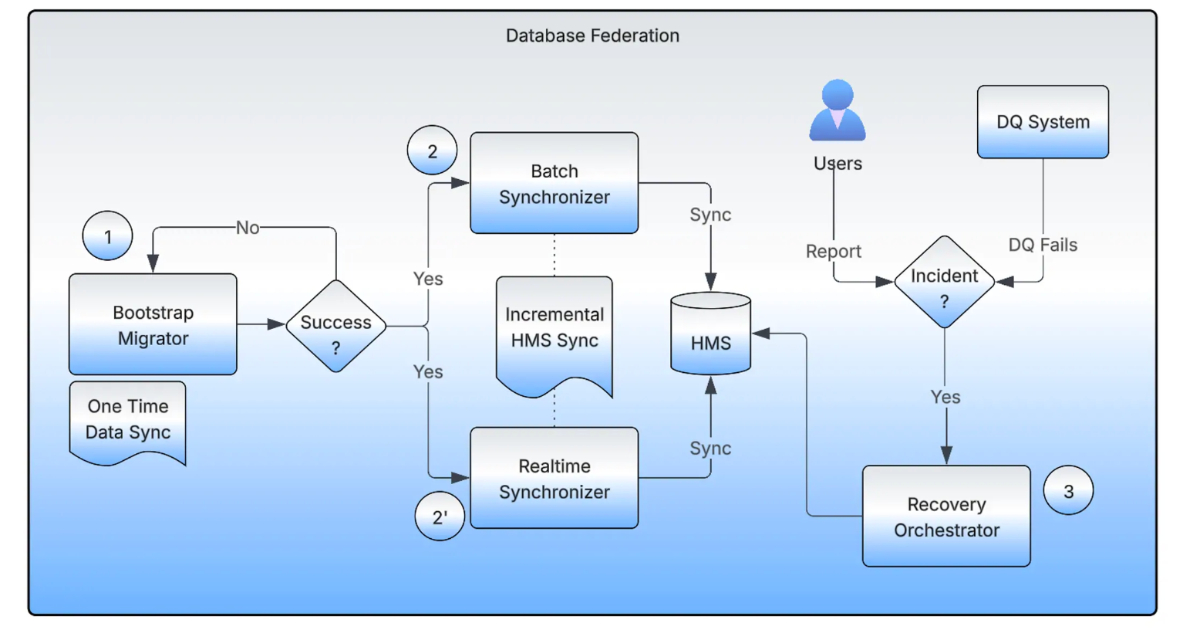
- A pointer-based migration strategy in Hive Metastore allows datasets to be redirected to new HDFS locations without data duplication, ensuring zero downtime.
- The new system comprises a Bootstrap Migrator, Realtime Synchronizer, Batch Synchronizer, and Recovery Orchestrator to manage the migration process.
- Decentralization enhances operational autonomy for domain teams, improves observability, compliance, and workflow efficiency.
- The migration reclaimed over 1 PB of HDFS space by removing stale datasets and reduces storage overhead.
- The approach improves resilience and reduces dependency on a central operations team.
📖 Source: Uber’s Hive Federation Decentralizes 16K Datasets and 10+ PB for Zero-Downtime Analytics at Scale
Related Articles
Comments (0)
No comments yet. Be the first to comment!